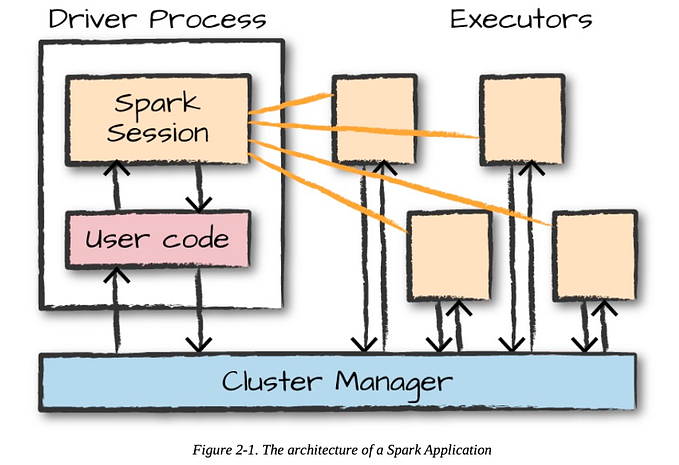
CSVToParquetLoader Orchestrator (Pandas > Spark > HDFS)

def resume_orchestration(self, start_from):
"""
Resume the orchestration process from the given start point.
"""
self.orchestrate(start_from=start_from)In a realm of data vast and wide, Where rows and columns in files reside. There lies a script, both deft and clever, To transform and load, ceasing never.
It starts with Spark, a trusty steed, A session set to meet our need, With memory fine and cores so steady, For tasks at hand, it stands ready.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("scalables")
.config("spark.executor.memory", "8g") # Memory per executor
.config("spark.executor.memoryOverhead", "1g") # Additional overhead
.config("spark.memory.fraction", "0.4") # Fraction of heap space used for execution and storage
.config("spark.memory.storageFraction", "0.6") # Fraction of memory used for storage (caching)
.config("spark.driver.memory", "8g") # Memory for Spark driver
.getOrCreate())CSVToParquetLoader is its name, Converting files, its claim to fame. From CSV format to Parquet's embrace, It moves each row, a delicate race.
A constructor first, with parameters clear, Paths and names that we hold dear, The chunksize small, the rows so many, It’s set to work without a penny.
def __init__(self, spark_session, input_path, output_path, filename, chunksize, total_rows, start_row=1):
"""
Initializes the CSVToParquetLoader with the necessary parameters.
"""
self.spark = spark_session
self.input_path = input_path
self.output_path = output_path
self.filename = filename
self.chunksize = chunksize
self.total_rows = total_rows
self.start_row = start_row# Example usage: 300 parquets
loader = LoadData(spark_session=spark,
input_path="path/to/input/data/",
output_path="hdfs:///path/to/output/data/",
filename="input_file_name.csv",
chunksize=10000,
total_rows=3000000)
The load_csv method takes its part, Reading chunks, it's quite the art. With progress bar that marches on, Until the file is good and gone.
True and False, to ones and zeros turn, In pandas’ land, where DataFrames churn. Concatenation then takes the stage, As chunks unite in a single page.
def load_csv(self, skiprows, n_rows=None):
"""
Loads a chunk of the CSV file into a pandas DataFrame, skipping the header after the first chunk.
:param skiprows: Number of rows to skip from the start of the file for this chunk.
:param n_rows: Number of rows to read. Reads till the end if None.
:return: pandas DataFrame containing the chunk.
"""
# Read in the first row to get the column names
names = pd.read_csv(os.path.join(self.input_path, self.filename), nrows=0).columns.tolist()
# Calculate the remaining rows if n_rows is not specified
if n_rows is None:
n_rows = self.total_rows - skiprows + 1
# Initialize a tqdm progress bar
pbar = tqdm(total=math.ceil(n_rows / self.chunksize), desc='Loading CSV')
# Initialize an empty DataFrame
data = pd.DataFrame(columns=names)
# Set the header flag depending on whether this is the first chunk or not
header_flag = None if skiprows == 0 else 0
# Read the file in chunks
for chunk in pd.read_csv(os.path.join(self.input_path, self.filename), chunksize=self.chunksize,
skiprows=range(1, skiprows) if skiprows else None, nrows=n_rows,
names=names, header=header_flag):
# Replace True/False with 1/0
chunk.replace([True, False], [1, 0], inplace=True)
# Append the chunk to the data DataFrame
data = pd.concat([data, chunk], ignore_index=True)
# Update the progress bar
pbar.update(1)
# Close the progress bar
pbar.close()
return dataAnd once the DataFrame is full and primed, write_to_hdfs takes its time. To Spark's domain, the data goes, Partitioned, where the fast wind blows.
def write_to_hdfs(self, df, partition):
"""
Writes the given pandas DataFrame to HDFS as a Parquet file.
:param df: pandas DataFrame to write.
:param partition: Partition number to append to the file name.
"""
# Convert pandas DataFrame to Spark DataFrame
df_spark = self.spark.createDataFrame(df)
# Write to HDFS without repartitioning
df_spark.write.mode('overwrite').parquet(os.path.join(self.output_path, f'raw_data_{partition}.parquet'))Now written down in HDFS’s keep, In Parquet form, compressed and deep. The orchestrate method, a conductor grand, Guides the process with a gentle hand.
def orchestrate(self, start_from=1):
"""
Coordinates the entire process of reading, converting, and writing data.
:param start_from: Partition number to start the process from.
"""
for i in range(start_from, self.total_rows, self.chunksize):
# Calculate the number of rows to read for the last chunk
n_rows = self.chunksize if i + self.chunksize <= self.total_rows else self.total_rows - i + 1
# Load CSV chunk
df = self.load_csv(i, n_rows=n_rows)
# Write to HDFS
self.write_to_hdfs(df, partition=math.ceil(i / self.chunksize))It slices the file into pieces so neat, Each a part of the total feat. And should an interruption come to pass, resume_orchestration saves your class.
It picks up where the work was left, Of no momentum are you bereft. From part two-eight-two or wherever you are, It carries on, near or far.
def resume_orchestration(self, start_from):
"""
Resume the orchestration process from the given start point.
"""
self.orchestrate(start_from=start_from)So behold the class with a task so pure, Turning CSVs to Parquets with allure. A dance of data, a symphony of files, CSVToParquetLoader does it with styles.
Now outside this class, should you seek to explore, The Parquet files, a treasure trove’s core. read_multiple_parquets_to_df, an open door, To stitch together what was once tore.
def read_multiple_parquets_to_df(spark_session, file_pattern):
"""
Read multiple Parquet files matching a pattern into a single DataFrame.
:param spark_session: The Spark session object.
:param file_pattern: The pattern to match files in HDFS.
:return: A DataFrame containing the data from all Parquet files matching the pattern.
"""
# Read all Parquet files matching the file pattern into a single DataFrame
df = spark_session.read.parquet(file_pattern)
return dfWith spark_session and pattern in hand, The files are read as if by command. A DataFrame returns, from the data's strand, Combined and ready, as your analysis planned.
So with this tale, the journey ends, But with the knowledge, your path extends. From CSVs to Parquets, the data transcends, And with Spark’s might, your will it bends.